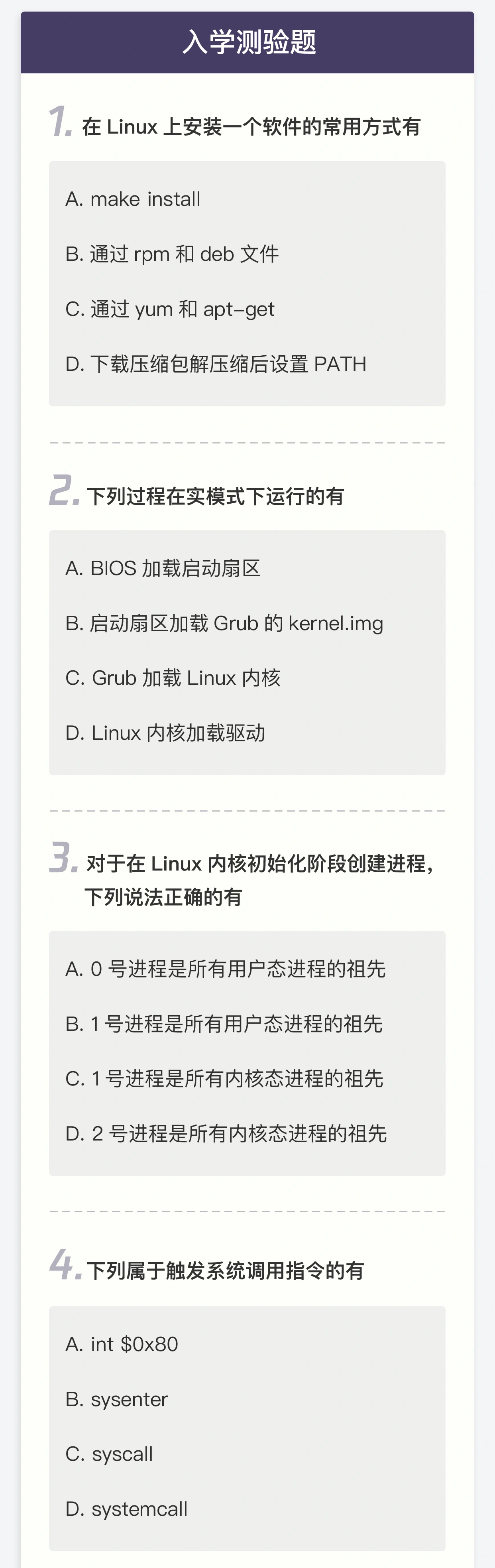
概述 功能
学习
开发: 产品基本功能,底层原理,数据建模
运维: 容量规划; 性能优化; 问题诊断; 滚动升级
方案: 搜索与如何解决搜索; 大数据分析实践,理论知识实际场景
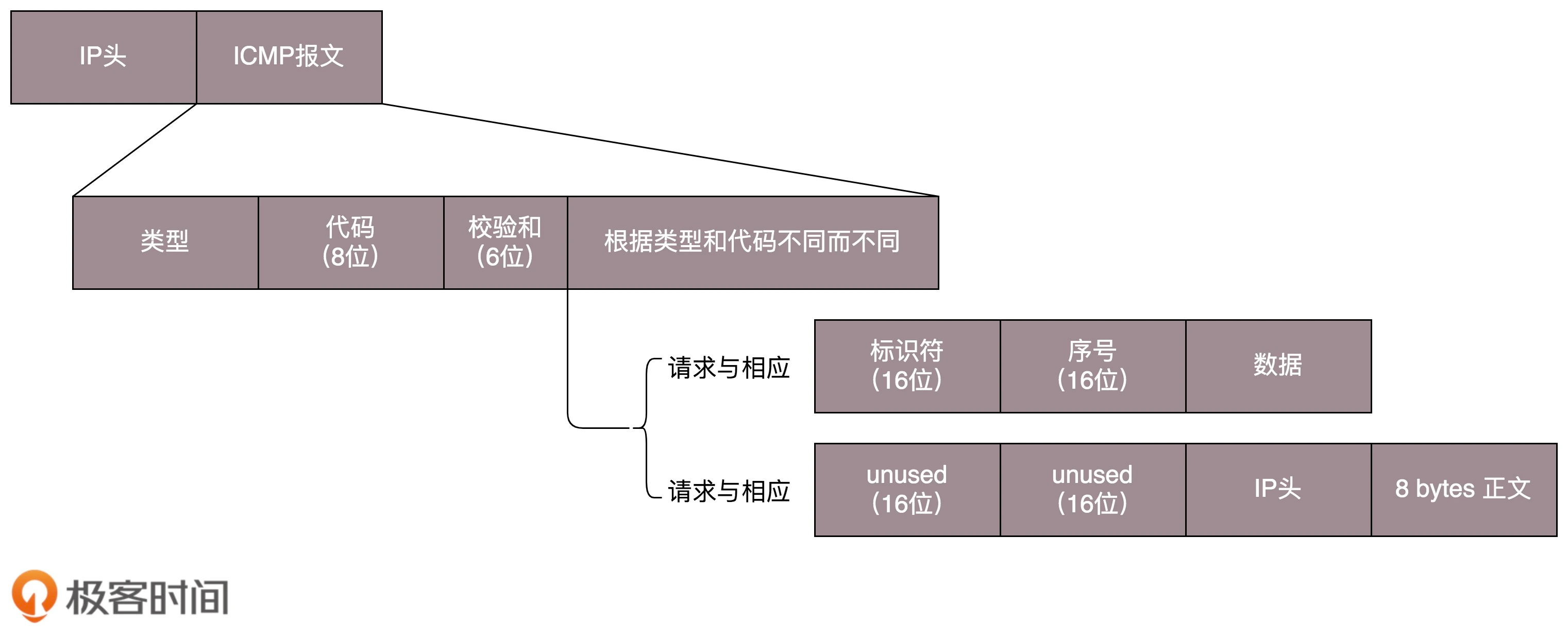
考试: elastic 官网 简介 1 2 3 restful 接口, 供各种语言使用 功能: 搜索,聚合
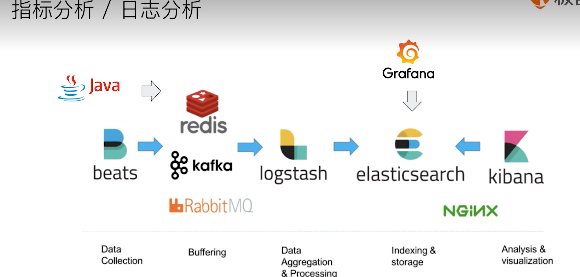
elastic 生态
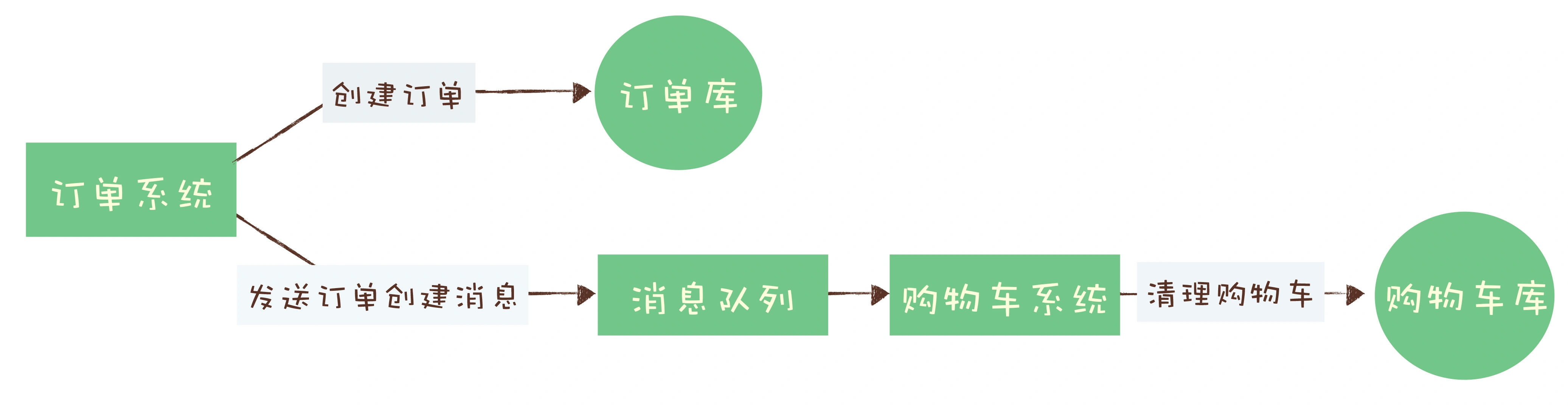
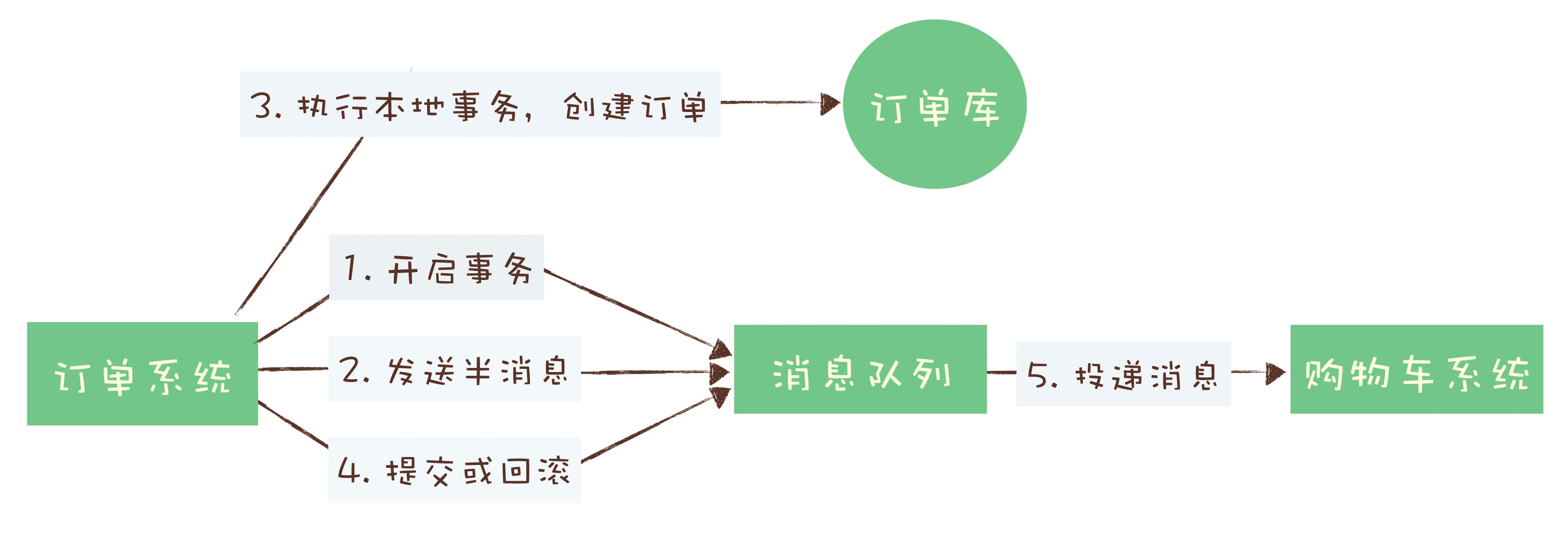
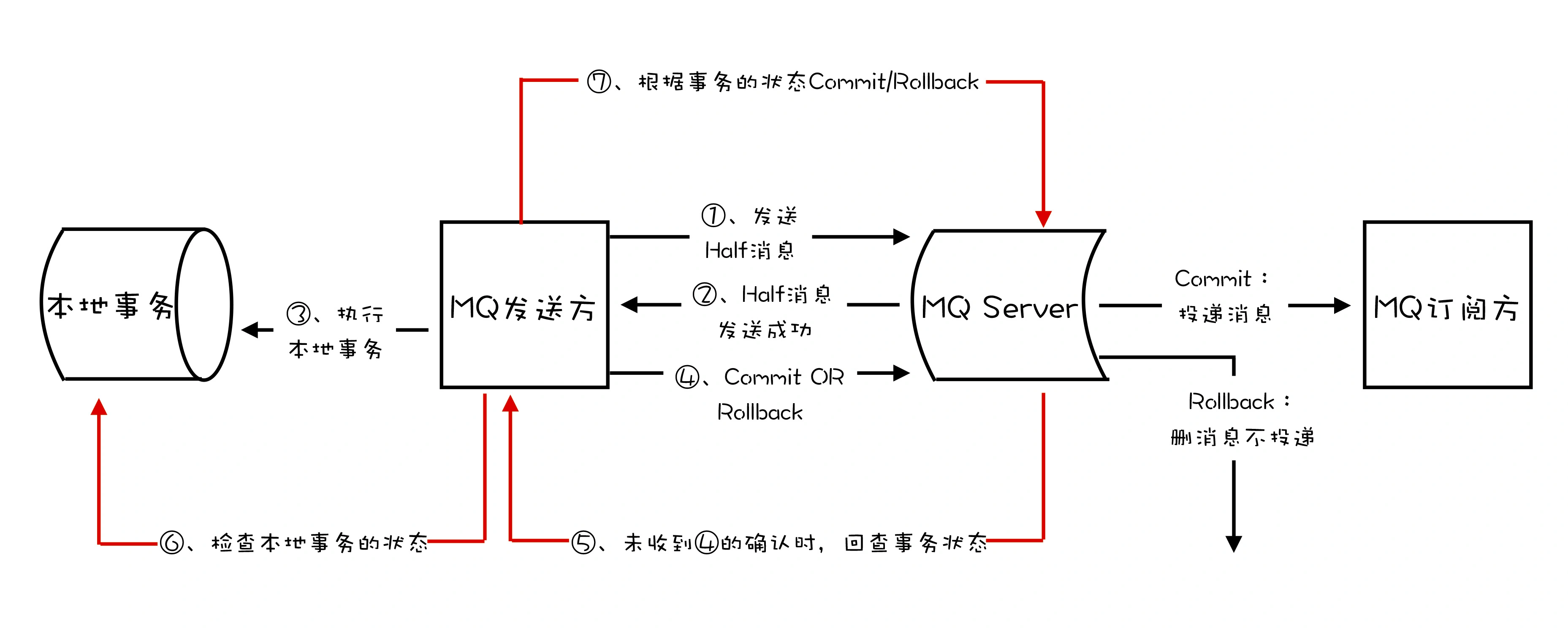
logstash 开源服务端数据处理管道, 从不同源采集数据,转换数据,发送到不同存储库
1 2 3 4 5 6 7 8 9 实时解析和转换数据 从IP地址破译地理位置 将PII(个人身份信息)数据匿名,排除敏感字段 可扩展 200多个插件 (日志、数据库。。。) 可靠安全性 持久化队列保证至少送达一次 数据传输加密 监控
1 2 数据可视化公司 基于 logstash 的工具, 2013被es收购
1 2 3 4 有多种不同的beat filebeat: 日志,文件 packetbeat: 网络数据抓包 。。。
场景
安装上手 安装
二进制文件 docker
helm chart for k8s
puppet module
文件目录结构
bin : 脚本执行文件 包括: 启动,安装插件,运行统计数据等
config : 集群配置文件
JDK : java运行环境
data : 数据文件
lib : java类库
logs : 日志文件
modules : 包含所有ES模块
plugins : 所有已安装插件
启动
1 2 3 4 5 6 7 /bin/elasticsearch 启动 /bin/elasticsearch-plugin 插件管理 install 安装 分布式 ./elasticsearch -E node.name=node1 -E cluster.name=geektime -E path.data=node1_data -d ./elasticsearch -E node.name=node2 -E cluster.name=geektime -E path.data=node2_data -d ./elasticsearch -E node.name=node3 -E cluster.name=geektime -E path.data=node3_data -d
入门 索引,文档,RESTAPI 文档 1 2 3 4 5 6 ES是面向文档的, 文档是可搜索数据的最小单位 文档会被 序列化为JSON格式,保存在ES中 (JSON对象由字段组成,每个字段有类型) 每个文档都有一个 唯一ID, 可以自己指定/或ES自动生成 类似数据的一条记录 JSON文档格式灵活,不需要预先定义格 (字段类型可以指定,也可以ES自动推算)(支持 数组/嵌套)
文档的元数据
1 2 3 4 5 6 7 8 ES用于标注文档的相关信息 _index 文档所属索引名称 _type 文档所属类型名称 _id 文档唯一ID _source 文档原始JSON数据 _version 文档版本信息 _score 相关性打分
索引 1 2 3 4 5 文档的容器, 一类文档的集合 体现逻辑空间的概念: 索引有自己的Mapping定义,定义包含文档的字段名和字段类型 索引的Mapping : 定义文档字段的类型 索引的Settings : 定义不同的数据分布
Shard 则是体现 物理空间的概念: 索引中的数据分散在 shard 上
1 2 3 索引的不同语意: 名称: 文档的集合, 可创建多个索引 动词: 保存一个文档到ES的过程 (在ES中是创建一个 倒排索引) (有B树索引 , 倒排索引)
类型 type
1 2 7.0 版本之前, 每个索引可以建立多个type, 每个type下就是同类文档 7.0开始废弃不用,每个索引只能建立一个type (_doc)
REST API 节点,集群,分片,副本 1 2 3 4 5 6 7 8 分布式系统的可用性和扩展性 高可用 服务可用: 允许有节点停止服务 数据可用: 部分节点丢失,不会丢失数据 可扩展: 请求量提升 / 数据不断增长 (将数据分布到所有节点上)
ES的分布式架构 1 2 3 4 5 6 7 不同的集群 通过不同名字区分 (默认名字 elasticsearch) 通过配置文件修改,或命令行 -E cluster.name=geektime 设定 一个集群可以有一个或多个节点 好处: 存储的水平扩容 提高系统的可用性,部分节点停止服务,整个集群服务不受影响
节点 1 2 3 4 5 节点: 一个 ES 的实例 本质就是一个JAVA进程 一台机器可运行多个ES进程,但生产环境一般建议一台机器一个实例 每个节点设置名字: 通过配置文件,或启动命令行 -E node.name=node1 指定 每个节点启动后,会分配一个UID,保存在 data 目录下
master-eligible nodes
1 2 3 4 可以参加 选主流程,成为master 节点 每个节点启动后: 默认就是一个 master eligible 节点 可设置 node.master: false 禁止
master node
1 2 当第一个节点启动时, 会将自己选举成 master 节点 每个节点都保存了集群的状态, 只有 master 节点才能修改集群的状态信息 (任何节点都能修改会导致数据不一致)
集群状态: 维护集群中的必要信息
所有节点的信息
所有索引 和 其相关的 Mapping 与 Setting 信息
分片的路由信息
Data Node
保存数据的节点,叫做Data Node, 负责保存分片数据 (在数据扩展 起重要作用)
Coordinating Node
负责接受client的请求,将请求分发到合适节点,最终把结果汇聚到一起。
每个节点默认起到 coordinating node 职责
Hot & Warm Node
冷热节点, Hot节点配置高, warm配置低(可存储比较旧的数据)
不同硬件配置的 Data Node, 用来实现 Hot & Warm 架构,降低集群部署的成本
Machine Learning Node
Tribe Node
连接到不同的 ES集群,支持将这些集群当成一个单独的集群处理
淘汰, 5.3开始使用 cross cluster search(跨集群搜索)
节点类型的配置: 生成环境中,应该设置单一角色的节点
节点类型
配置参数
默认值
master eligible
node.master
true
data
Node.data
true
ingest
node.ingest
True
coordinating only
无
每个节点默认都是coordinating节点。设置其他类型则为false
machine learning
node.ml
true (需 enable x-pack )
分片
主分片 ( primary shard )
1 2 3 解决数据水平扩展的问题。 主分片可以将数据分布到集群内的所有节点之上 一个分片 是一个运行的 lucene 的实例 主分片数 在索引创建时指定, 后续不允许修改, 除非 Reindex
副本 ( replica shard )
1 2 3 用以解决数据高可用的问题。 副本分片是主分片的拷贝 副本分片数 可以动态调整 增加副本数,还可在一定程度上提高服务的可用性 ( 读取的吞吐 )
分片的设置: 生成环境分片的设定,提前做好容量规划
1 2 3 4 5 6 分片数设置过小: 后续无法增加及节点实现水平扩展 单个分片数据量太大,导致数据重新分配耗时 分片数设置过大, 7.0 开始, 默认主分片设置成1, 解决了 over-sharding 的问题 影响搜索结果的 相关性打分,影响 统计结果的准确性 单个节点上过多的分片,会导致资源浪费, 同时也会影响性能
1 2 3 4 5 6 查看 集群健康状况 GET _cluster/health green - 主分片 和 副本 都正常 yellow - 主分片正常, 有副本分片未正常分配 red - 有主分片未能分配 (例: 当服务器磁盘容量超过 85% 时, 去创建了一个新的索引
文档的基本 CRUD
操作
命令 (type约定用_dec)
说明
Index
PUT my_index/_doc/1
如果ID不存在,创建信息的。 已经存在则删除旧的创建新的,版本号增加
Create
PUT my_index/_create/1
如果id已经存在,会失败
Read
GET my_index/_doc/1
Update
POST my_index/_update/1
文档必须已经存在, 更新只会对相应字段做增量修改
Delete
DELETE my_index/_doc/1
创建说明 1 2 3 4 支持 自动生成文档ID 和 指定文档ID 两种方式 通过调用 POST /my_index/_doc (系统自动创建ID) 通过 PUT /my_index/_create/1 创建, 指定 _create , 如果ID文档已存在,操作失败
注意: create是创建新的, index 是 删除旧的创建新的, update是在旧的上面做增量修改
批量操作
Bulk API
1 2 3 4 5 6 7 8 9 POST _bulk 支持一次API调用中, 对不同索引进行不同操作 支持四种操作: Index, Creat, Update, Delete 可以在 URI 中指定Index, 也可以再请求 payload 中进行 操作中 单条操作失败, 并不会影响其他操作 返回结果包括 每一条操作执行的结果
mget 批量读取
msearch 批量查询
常见错误返回
1 2 3 4 5 无法连接: 网络故障或集群挂了 连接无法关闭: 网络故障或节点出错 429 : 集群过于繁忙 4xx : 请求体格式错误 500 : 集群内部错误
注意: 批量操作一次请求不宜过多
倒排索引 书本对比理解 1 2 3 4 书本开始: 有目录,书本内容的索引 - 正排索引 根据目录中的 章节名称对应页码 查询具体内容 有一些书本最后: 有一些重要内容对应页码的索引页 - 倒排索引
搜索引擎中 1 2 正排索引: 文档ID 到 文档内容和单词 的关联 倒排索引: 单词 到 文档ID 的关系
一个例子:
1 2 左边正排索引, 三篇 es书 的文档 右边倒排索引, 所有词条的索引,出现次数, 在哪个文档中哪个位置
倒排索引的核心组成
单词词典( term dictionary ), 记录所有文档的单词, 记录单词 到 倒排列表 的关联关系
单词词典很大, 通过 B+树 或 哈希拉链法实现, 满足高性能的插入和查询
倒排列表 ( posting list ) , 记录了 单词对应的文档 的结合, 由倒排索引项组成
倒排索引项(posting)
文档ID
词频 TF - 该单词在文档中出现的次数, 用于相关性评分
位置(position) - 单词在文档中分词的位置。 用于 语句搜索
偏移(offset)-记录单词的开始结束位置, 实现高亮显示
上面例子在 ES中的实现
ES中 JSON文档每个字段都有自己的 倒排索引
可以指定 对某些字段不做索引
通过 analyzer 进行分词 1 2 3 4 5 6 analysis 文本分析: 把全文本转换为 一系列单词 (term / token)的过程, 也叫 分词 analysis 通过 analyzer 实现 可使用ES内置的分析器 / 或按需定制化分析器 除了 数据写入时 转换词条, 匹配Query语句时也需要用相同的分析器对查询语句进行分享
分词器是专门 处理分词的组件, analyzer 由三部分组成 (按顺序执行)
character filters ( 针对原始文本处理, 例如去除html )
Tokenizer ( 按照规则切分为 单词 )
Token Filter ( 将切分的单词进行加工, 小写,删除 stopwords,增加同义词 )
ES内置分词器
standard analyzer - 默认分词器,按词切分,小写处理
simple - 按 非字母切分 (符号被过滤), 小写处理
stop - 小写处理, 停止词过滤(the,a,is)
whitespace - 按空格切分,不转小写
keyword - 不分词,直接将输入当做输出
patter - 正则表达式, 默认 \W+ (非字符分割)
language - 提供 30多种常见语言的分词器
customer - 自定义分词器
使用 _analyzer API 1 2 GET /_analyze // 直接指定 analyzer 进行测试 对文本如何分词 {"analyzer":"standard", "text":""}
1 2 POST my_index/_analyze // 指定索引字段, 查看 该字段如何进行分词 {"field":"", "text":""}
1 2 POST /_analyze // 自定义分词测试, 定义一个tokenizer,定义fileter, 组合后 是如何进行分词的 {"tokenizer":"standard","filter":[""], text:""}
中文分词 的难点 1 2 3 中文句子,切分成一个个词 (而不是字) 英文,单词有自然的空格作为分割 中文,在不同上下文有不同理解
ICU Analyzer
1 2 安装plugin: elasticsearch-plugin install analysis-icu 提供unicode支持,更好支持亚洲语言
IK
THULAC
1 清华大学自然语言处理 和 社会人文计算实验室的一套中文分词器
Search API
URI search
Request Body search
使用 ES 提供的, 基于JSON格式的更加完备的 Query Domain Specific Language (DSL)
1 2 3 4 5 指定查询的索引 /_search 集群上所有的索引 /index1/_search 索引index1 /index1,index2/_search 索引 index1,2 /index*/_search 以index开头的索引
搜索的相关性 1 2 3 4 5 6 搜索是: 用户 和 搜索引擎 的对话 用户关心的是: 搜索结果的相关系 是否可以找到所有相关的内容 有多少不相关的内容被返回了 文档的打分是否合理 结合业务需求,平衡结果排名
Web 搜索
page rank 算法 (不仅仅是内容,更重要的是内容的可信度)
电商搜索
扮演 销售的角色
提高用户购物体验,提升网站销售业绩,去库存
衡量相关性 学科 information Retrieval
1 2 3 precision (查准率) - 尽可能返回较少的无关文档 recall (查全率) - 尽可能返回较多的相关文档 ranking - 是否能够按照相关度进行排序
URI search 详解 1 2 3 4 5 通过 URI query 实现搜索 q指定查询语句: 使用 df 默认字段, 不指定会对所有字段进行查询 sort 排序 / from 和 size 用于分页 profile 查看 查询是如何被执行的
Request Body 与 Query DSL 介绍
将查询语句通过 HTTP Request Body 发送给 ES
Query DSL
1 2 3 4 5 6 7 8 ``` ## Query string 与 Simple Query string ## Dynamic Mapping 和 常见字段类型 ### Mapping
类似于 数据库中的 schema 的定义, 作用:
Mapping 会把 JSON文档 映射成 Lucene 所需要的扁平格式
一个Mapping属于一个索引的Type ( 7.0 开始一个索引一个type )
写入文档时: 如果索引不存在,自动创建索引
有时候会推算不对,如地理信息 (类型不对,会导致一些功能出错)1 2 3 4 5 - 能否更改mapping的字段类型 - 新增字段
1 2 3 4 5 6 7 - 原因 - 修改字段的数据类型, 导致已被索引的数据无法被搜索 - 增加新的字段不会有影响 ## 显示Mapping的设置与常见参数介绍
PUT movies
建议:
控制当前字段是否被索引: 默认为true, 如果要设置为不可被搜索,字段添加设置 “index”:false
null_value, 需要对null值实现搜索: 只有keyword类型支持设定 “Null_value”:”NULL”
_all 在版本7中被 copy_to 所替代: copy_to 将字段的数值拷贝到目标字段(如 firstName,lastName 两个字段拷贝到 fullName,实现全名称搜索), copy_to 目标字段不出现在_source 中
数组类型: ES不提供专门的数组类型。 但任何字段,都可以包含多个相同类型的数值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 - 控制 倒排索引 记录内容的配置 - docs - 记录 doc id - freqs - 记录 doc id 和 term frequencies - positions - 记录 doc id / term frequencies / term position - offsets - 记录 doc id / term frequencies / term position / character offects - Text 类型默认记录 postions, 其他默认为 docs - 记录内容越多,占用存储空间越大 ## 多字段特性 及 mapping中配置自定义 Analyzer - 多字段特性 - 厂商名字实现精确匹配 - 增加一个 keyword 字段 - 使用不同的 analyzer - 不同语言 - pinyin 字段的搜索 ( 中文实现拼音搜索) - 支持为 搜索和索引 指定不同的analyzer
Excat values : 包括 数字 / 日期 / 具体一个字符串 (ES中的 keyword)(在索引时,不分词)
当ES自带的分词器 无法满足,可以自定义分词器。 通过自组合不同组件实现:
Tokenizer :
将原始文本安装一定规则,切分为词 ( term or token )
ES内置的: whitspace / standard / uax_url_email / pattern / keyword / path hierarchy
可使用Java开发插件,实现自己的Tokenizer
Token Filter :
将Tokenizer 输出的单词( term ), 进行增加,修改,删除
ES自带的 Token Filters: lowercase(小写) / stop(停止词) / synonym(添加近义词)
创建索引时, 在 settings 中 自定义 analysis
1 2 3 4 5 6 7 8 ## Index Template 和 Dynamic Template - Index template - 帮助设置 Mappings 和 Settings, 并按照一定规则,自动匹配到新创建的索引之上 - 模板 仅在一个索引被新创建时,才会产生作用。 修改模板不会影响已创建的索引 - 可设置多个 索引 模板, 这些设置会被 "merge" 在一起 - 可指定 "order" 的数值, 控制 "merging"的过程
当一个索引 被新创建时
1 2 3 4 5 6 - Dynamic Template : 根据ES识别的数据类型,结合字段名称,动态设定 字段类型 - 所有 字符串类型设定成 keyword, 或关闭 keyword - is 开头的字段都设置成 boolean - long_ 开头的都设置成 long 类型
Dynamic Template 定义在 某个索引的 Mapping 中
1 2 3 4 5 ## ES 聚合分析介绍 ### 聚合 ( aggregation )
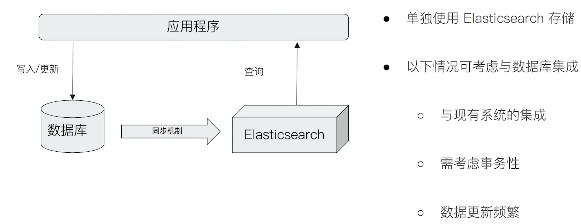
ES 除搜索外,提供 针对ES数据进行统计分析的功能
kibana 可视化报表 - ES的聚合分析
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 - 聚合的分类 - Bucket Aggregation - 满足特定条件文档 - Term & Range ( 时间 / 年龄区间 / 地理位置 ) - Metric Aggregation - 一些数学运算, 可以对文档字段进行统计分析 - 基于数据集 计算结果, 支持字段上的计算,也支持脚本产生的结果上计算 - 数字计算,输出一个值: min / max / sum / avg / cardinality - 输出多个值: stats / percentiles / percentile_ranks - Pipeline Aggregation - 对其他聚合结果进行二次聚合 - Matrix Aggregation - 支持对多个字段的操作并提供一个结果矩阵 # 深入搜索 ## 基于词项和基于全文的搜索 ### 基于Term的查询 - Term : 表达语意的最小单位。 搜索 和 利用统计语言模型进行自然语言处理 都需要处理Term - 特点: - Term Level Query: Term / Range / Exists / Prefix / wildcard - Term查询,对输入不做分词。 在倒排索引中查找准确的词项,并为每个包含该词项的文档进行 相关度算分 - 可以通过复合查询 Constant Score 将查询转换成一个 Filtering, 跳过算分,并可以有效利用缓存, 提高性能 ### 基于全文的查询 - Match Query / Match Phrase Query / Query String Query - 特点: - 索引 和 搜索 时都会进行分词, 查询字符串先传递到一个合适的分词器,生成一个供查询的词项列表 - 查询过程,先 对输入的查询进行分词, 然后每个词项逐个进行底层的查询打分,最终将结果汇总。 为每个文档生成一个算分。 ## 结构化搜索 - 对 结构化数据 的搜索 - 日期,布尔,数字 都是结构化的。 有精确的格式,可以对这些格式进行逻辑操作。 范围,大小等 - 文本也可以结构化 - 可以做 精确匹配 或者 部分匹配 ( term查询 / prefix前缀查询 等) - 结构化结果只有 "是" 或 "否" 两个值。 根据场景需要决定是否需要打分 ## 搜索的相关性算分 ### 相关性
搜索的相关性算分: 描述 文档 和 查询语句 匹配的程度。 ES会对每个匹配查询条件的结果进行算分 _score
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 ### TF-IDF - 词频 TF ( Term Frequency ) : 检索词在一篇文档中出现的频率 - 检索词出现的次数 除以 文档的总字数 - 度量一条查询和结果文档相关性的简单方法: 将搜索中每个词的TF进行相加 - Stop Word (停止词) , 如"的", 在文档中出现很多次,但对贡献相关度几乎没有用处,不应考虑它们的TF - 逆文档频率IDF ( Inverse Document Frequency ) : - DF: 检索词在所有文档中出现的频率 - 而IDF, 简单说就是公式: log(全部文档数 / 检索词出现过的文档总数) - TF-IDF 本质上就是将 TF 求和 变成了 加权求和 - 例子: 搜索 区块链的应用 ( 分词为: 区块链 的 应用 三个词)
TF(区块链)*IDF(区块链) + TF(的)*IDF(的) + TF(应用)*IDF(应用)
和经典的TF-IDF, 当TF无限增加时, BM25算分会趋于一个数值
PUT /my_index
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 ### Boosting Relevance - Boosting 控制相关度的一种手段 ( 索引,字段 或查询子条件) - 含义: - boost > 1 时, 打分相关度 相对性的提升 - 0 < boost < 1 , 打分权重 降低 - boost < 0 , 贡献负分 ## Query & Filtering 与 多字符串多字段查询 - 高级搜索的功能: 支持多选 文本 输入, 针对多个字段进行搜索 - 搜索引擎 一般也提供 基于时间,价格等条件的过滤 - 在ES中, 有 Query 和 Filter 两种不同的 Context - Query Context:相关性算分 - Filter Context: 不算分,利用缓存,更好性能 ### bool 查询 - 一个 或者 多个 查询子句的组合 ( 4种子句) - 相关性 除了全文本检索, 也使用 yes|no 的子句, 匹配子句越多,评分越高 - 子查询顺序任意, 可嵌套多个查询 - must : 必须匹配,贡献算分 - should : 选择性匹配, 贡献算分 - must_not :必须不匹配, 是 filter context, 不贡献算分 - filter : 过滤条件,必须匹配, 是 filter context, 不贡献算分 - 结构化查询 : 包含而不是相等 的问题 (多值字段 ) - 增加一个 count 字段进行计数 - 查询语句的结构, 对相关度算分的影响 - 同一层级的竞争字段,具有相同的权重 - 通过 嵌套bool查询,可以改变 对算分的影响 ## 单字符串多字段查询 - should 算分过程 - 查询 should 语句中的两个查询 - 加和 两个查询的评分 - 乘以 匹配语句的总数 - 除以 所有语句的总数 ### Dis Max Query
两字段竞争,不应 将分数简单叠加,应该找到单个最佳匹配的字段的评分
1 2 3 4 5 6 7 - dis max query - 将任何 与 任一查询匹配的文档作为结果返回。 采用字段上最匹配的评分作为 最终评分返回 - 通过 tie_breaker 参数调整,将其他匹配语句的评分与tie_breaker 相乘,最终结果为 将最佳匹配评分与tie算法相加 (tie_breaker 介于 0-1, 0:使用最佳匹配,1:所有语句同等重要) ### Multi Match
三种场景:
POST my_index/_search
跨字段搜索
cross_fields 类型的 multi_match
1 2 3 4 5 ## 多语言 及 中文分词与检索 ### 多语言
不同索引使用不同语言
挑战:
技巧:
1 2 3 4 5 6 7 ### 中文分词 - 常用中文分词器: hanLP / IK / pinyin - 演变
查字典, (有的词就标示,复合词就找最长的。 不认识就分割成单字)
最小词数的分词理论 ( 一句话分词数量最少的词串, 二义性分割不行)
统计语言模型 ( 解决二义性问题, 将中文分词错误率降低。 概率问题: 动态规划+利用维特比算法 )
基于统计的机器学习算法 ( HMM,CRF,SVM,深度学习等算法, 基本思路是对汉字进行标注训练。。。)1 2 3 4 5 ## Search Template 和 Index Alias 查询 ### search Template - 解耦程序 & 搜索DSL
在开发初期, 可以明确查询参数,但往往还不能最终定义查询的DSL的具体结构
各司其职,解耦
创建一个 search Template POST _scripts/tmdb
搜索工程师 维护 search Template
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 ### Index Alias - 别名: 实现零停机运维 ## 综合查询: function score query 优化算分 - 算分与排序 - ES默认会以 文档的相关度算法进行排序 - 可以通过指定 一个或多个字段进行排序 - 使用相关度算分(score)排序,不能满足某些特定条件 - 无法针对相关度,对排序实现更多控制 ### Function Score Query
可以在查询结束后, 对每一个匹配的文档进行 一系列的重新算分, 根据新生成的分数进行排序
默认计算分值的函数:
Field Value Factor: 使用该数值修改 _score, 例如将 "热度","点赞数"作为算分的参考因素。
新的算分=老的算分*热度 (问题,热度数值差异很大 0和10000,结果分数差异过大)
使用 modifier 平滑曲线(使用各种 公式计算):如log1p, 则 新的算分 = 老的算分 * log(1+热度)
Random Score: 为每一个用户使用一个不同的 随机算分结果
(网站广告提高展现率, 让每个用户看到不同的随机排名,但是也希望同一个用户访问时,结果的相对顺序保持一致)
衰减函数: 以某个字段的值为标准,距离某个值越近,得分越高
Script Score: 自定义脚本完全控制所需逻辑
1 2 3 4 5 6 7 8 9 10 11 ## Suggester ```text 用户在输入过程 自动补全或者纠错的功能 在ES中 suggester API 实现 原理: 将输入的文本分解为token,然后在索引的字典里查找相似的term返回 ES中设计了 4中类别的 Suggester Term & Phrase Suggester Complete & Context Suggester