对旧代码进行review
- 业务说明
- 设计思路
- 代码层次结构
- 代码逻辑说明
- 代码好的地方
- 代码坏的地方
- 代码实现经典之处
- 代码实现缺陷遗漏之处
对新代码如何进行review
参考文章 <<如何在团队中做好Code Review>> , 基本全拷贝,去看这篇文章就可以了
好处
你有一个苹果,我有一个苹果,彼此交换一下,我们仍然是各有一个苹果;但你有一种思想,我有一种思想,彼此交换,我们就都有了两种思想,甚至更多。
在大部分团队,尤其是微服务架构的团队。 通常是一个人员负责多个服务/项目, 如果没有code review, 项目中设计的架构知识,业务知识就只存在于项目过程中产出的说明文档了。
(像我们甚至文档都比较少的)很多设计内容基本只存在于开发人员脑子里。 时间久了,自己都会忘,别人要维护就更难了。
code review 的过程, 至少 Reviewer 必须阅读文档,看代码是否实现相同。 知识的传播性更好,基本不会只有一个人了解某个项目的情况了。
代码质量等级: 可以编译通过->可以正常运行->可以测试通过->容易阅读->容易维护 。 Code Review的代码最起码可以达到易阅读这个级别
要做到易阅读,不是只要有Code Review这个环节就可以了,还要有相关的规范,让大家按照同样的工程风格、编码风格去构建项目和编写代码。
统一风格一方面是让大家无论是维护项目还是阅读代码,不用互相适应各自的编码习惯,另外也是给Reviewer一个Code Review的基本依据。
发现Bug不是Code Review的必需品,而是附属品。至于那些低级的问题/bug交给代码扫描工具就可以了,这不是Code Review的职责。
推动code review落地执行
工具
gitlab, 每个项目不同角色, 在合并过程进行 code review
开发规范
- 工程规范 (工程结构,分层方式,命名等)
- 命令规范 (接口,类,方法名,变量名)
- 代码格式 (括号,空格,换行,缩进)
- 注释规范 (规定必要的注释)
- 日志规范 (合理的记录必要的日志)
- 各种推荐和不推荐的代码示例
规范学习网址:
- Go Code Review Comments(Go官方编程规范翻译)
- Uber 开源的《Go 语言编码规范
- Go 最佳实践: 编写可维护 Go 代码
指定流程规范
CodeReview建议是放在代码提交测试前,也就是开发人员完成代码开发及自测后将代码提交到测试分支时进行Code Review。毕竟,如果测试通过后再进行Code
Review,如果需要代码变更,势必会增加测试的工作量,甚至影响项目进度。亦或是顶着项目上线的压力,干脆“以后再说”了
以一般的git 工作流程来说, 就是 功能分支 feature 合并到 开发者分支 develop的时候进行 code review
指定角色行为规范
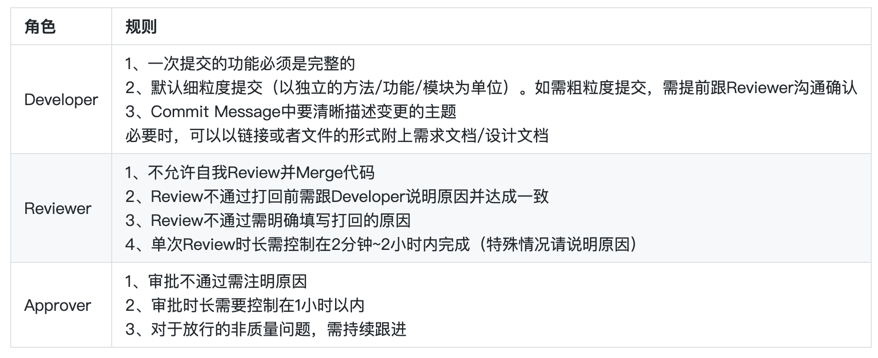
规范的目的:
- 控制提交Code Review的代码的粒度
- 控制单次Code Review的时间
- 提升Commit/MergeRequest描述的质量,减少沟通成本
通过细粒度高频次的方式尽可能利用工程师碎片化的时间进行Code Review,一定程度上保证Code Review的效率。
分享与统计
对code review 的过程及结果进行检验
我们期望CodeReview可以让工程师之间互相学习的,那么对于一次Code Review通常只有参与的2-3个工程师有互相学习的机会,那么在这个过程中学到的知识,定期的分享出来,既可以加强知识的流动,又可以检查大家究竟有没有在Code
Review过程中学习到知识,或者有没有认真的进行Code Review
至于分享的内容,可以是开发规范中的范例代码,也可以是规范中的正例代码,也可以是针对某个功能实现的最佳算法/最佳实践,也可以是Code Review过程中的争议代码,也可以是自己踩过的坑。
为了在一定程度上保证Code Review的效率,我们在规范里是要求参与的工程师:
1
2
3
| 1.Developer控制提交Code Review的粒度,或者控制每个Commit的粒度
2.Developer要准确清晰的描述所提交的代码
3.Reviewer&Approver要在规定时间内完成Code Review
|
这些情况纯粹靠人工是无法检验的,还是需要有一定的数据统计。
1
2
| 如果用Gerrit,可以查询Gerrit的数据库,里面会有Code Review的信息,
如果用GitLab,可以通过WebHook或者restful API获取Code Review信息
|
我们可以做成报表,来展示Code Review的情况:
1
2
3
4
5
| 1.每人每周Code Review所消耗的时间
2.每人每周被Code Review所消耗的平均时间
3.超过规定时间的Code Review情况
4.代码提交描述字数过少的情况
5.等等(根据自己的需要来)
|
保证code review质量的关键
- 工程师 对研发规范的认真学习
- 资深工程师的认真对待